.png)






Publicado em
06/2026
O Capela é um aplicativo católico da Biblioteca Católica. Ele reúne liturgia diária, Bíblia, orações, novenas, Rosário, exame de consciência, anotações espirituais e planos de vida em um só lugar. Hoje, cerca de 300 mil pessoas usam o app, sustentando uma nota 5 nas lojas.
Este artigo é sobre uma parte específica dessa operação, desenvolvida em parceria com o time de Software Development da Fleye: o Plano de Vida. Nele, o usuário organiza práticas e orações dentro da própria rotina. Ele escolhe o que quer rezar ou praticar, define um horário, configura uma recorrência e depois acompanha se cumpriu aquilo ao longo dos dias.
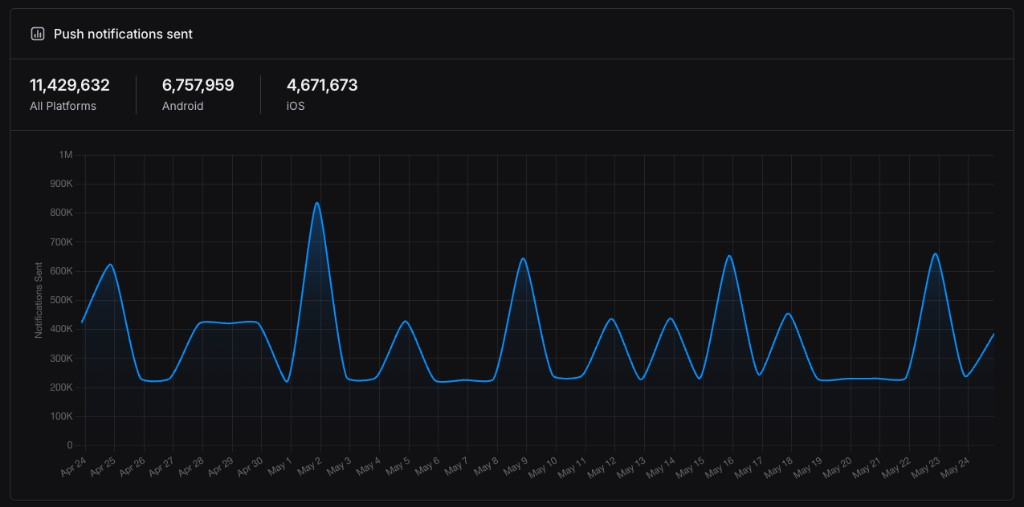
Atualmente, o sistema suporta a escalabilidade de notificações disparando mais de 11 milhões de mensagens de plano de vida por mês. Essa funcionalidade parece pequena quando descrita assim, mas ela carrega um desafio de arquitetura complexo: como representar agendamentos recorrentes que podem não ter data fim, possuem exceções em dias específicos e ainda precisam mudar sem travar a experiência no app para milhares de usuários?
Como lidar com agendamentos recorrentes sem data de fim no backend?
Essa ideia não é errada; pelo contrário, ela deixa muita coisa mais óbvia. Se a ocorrência existe como registro próprio, listar é simples, editar é simples e cancelar também parece simples. O problema começa no "até quando":
- - Prática semanal, todo sábado às 7h
- - Gerar 3 meses para frente?
- - Gerar 1 ano?
- - Gerar 10 anos?
Se geramos 3 meses, uma ocorrência daqui a um ano não existe. Se geramos 10 anos, qualquer mudança na série pode virar um update massivo em cima de um futuro que talvez o usuário nunca veja. E a edição de recorrência costuma ser justamente onde o modelo começa a pesar:
- - Usuário muda o horário de uma prática semanal
- - Atualizar a regra
- - Atualizar as ocorrências futuras já criadas
- - Cancelar agendamentos antigos
- - Criar novos agendamentos
Ainda sobra outra pergunta: quando regenerar o futuro? No create? No update? Em um job diário? Quando o usuário abre o app? Cada resposta cria um comportamento diferente.
A Solução: Expansão sob demanda e Overrides
No Plano de Vida, a combinação pode ser muito complexa: recorrência sem data fim, exceções por dia específico, marcação de feito e edição parcial da série. Gerar ocorrência futura nos faria escolher uma janela artificial e depois pagar o custo dela em toda mudança relevante.
O caminho oposto é não gerar nada com antecedência. Guardamos só a configuração da recorrência e a expandimos sob demanda. Isso acontece em dois lugares:
- Quando o usuário abre o app e a tela precisa mostrar os próximos dias.
- Quando o agendamento dispara e o backend precisa decidir se aquela ocorrência vira notificação.
Nenhum dos dois consulta uma lista de ocorrências futuras pré-geradas. O sistema consulta a regra e calcula o que precisa na hora. A exceção entra como desvio pontual em cima da regra. Se o usuário pulou um sábado, marcou como feito antes da hora ou trocou só o horário daquele dia, salvamos isso. Não é uma instância da série; é um override em cima da regra para aquela data específica. No momento do disparo, o backend consulta a regra e as exceções juntas: a regra diz que tinha que rolar agora, e as exceções dizem se esse "agora" deve mesmo virar notificação.
E se o usuário mudar a recorrência daqui para frente? Esse caso é diferente de exceção. Exceção é um dia específico saindo do padrão; "daqui para frente" é o padrão em si que muda a partir de uma data.
Quebramos esse caso em duas recorrências em sequência: a antiga ganha uma data fim no dia da mudança, e uma nova começa ali com a configuração nova. Ocorrências que ainda não dispararam continuam coerentes: as que vêm antes do corte seguem a regra antiga, as depois seguem a nova.
Cada regra fica simples; nenhuma das duas carrega complexidades do tipo "a partir de tal dia, mude o horário".
Resumindo as responsabilidades da arquitetura:
- - Regra de recorrência: Descreve a série.
- - Ocorrência específica: Só vira exceção quando o usuário mexe nela.
- - Agendamento: Dispara no horário configurado.
- - Backend: Decide se aquele disparo ainda deve virar notificação.
Por que escolhemos o EventBridge Scheduler na AWS?
Escolhemos o EventBridge Scheduler porque a parte de agendamento não era onde fazia sentido construir infraestrutura própria. Com o volume que temos hoje, qualquer solução baseada em worker varrendo registros, cron interno ou fila atrasada feita em casa acabaria criando uma operação paralela só para responder uma única pergunta: "tem algo para disparar agora?".
O Scheduler já nasce como um serviço gerenciado e focado em arquitetura serverless AWS para esse tipo de problema. Ele suporta schedules únicos e recorrentes e consegue acionar diretamente outros serviços da nuvem, como AWS Lambda e Amazon SQS.
Na época do desenho inicial, a gente não sabia qual seria a demanda real dessa feature. O Plano de Vida podia virar algo usado por uma parte pequena da base ou podia entrar na rotina diária de muita gente. Dimensionar capacidade fixa no chute era overengineering para um cenário desconhecido — sem falar no custo desperdiçado de infraestrutura.
Serverless é exatamente o tipo de stack que se adequa a esse cenário: você paga pelo uso real e não pede chute de capacidade adiantado. O EventBridge Scheduler foi construído para alta escala.
Para uma operação que faz mais de 11 milhões de notificações por mês, fazia total sentido usar um serviço gerenciado para cuidar da cadência dos agendamentos em vez de manter infraestrutura própria. A partir daí, o limite real passa a ser menos o serviço de agendamento e mais o pico de execução e as dependências que a Lambda toca.
Quais são as limitações do EventBridge Scheduler no produto?
O Scheduler não resolve tudo sozinho. Ele não tem o conceito de exceção que a regra de negócio precisa. Ele não sabe se o usuário marcou a prática como feita ou se uma ocorrência específica não deve notificar. Portanto, a responsabilidade dele termina estritamente no disparo.
[EventBridge Scheduler] ──(Invoca o target no horário)──> [Backend do Capela] ──(Valida exceções)──> [Notificação]
Na prática, isso evita depender do Scheduler para uma coisa que ele não modela: exceções de produto.
Características importantes de configuração
Autocleanup: O EventBridge permite apagar schedules automaticamente depois da última execução. Para uma novena, jornada ou qualquer prática com data de fim, é um recurso útil que evita termos que manter um job de limpeza para apagar schedules concluídos.
Janela Flexível Desligada: O EventBridge Scheduler trabalha com precisão de 60 segundos quando não existe janela flexível configurada.
- - Se agendamos algo para as 7h, a invocação acontece entre 7:00:00 e 7:00:59. Dá para configurar uma janela flexível para espalhar execuções dentro dos próximos 15 minutos, por exemplo. Mas para lembrete de rotina, isso precisa ser tratado com cuidado. Uma coisa é atrasar uma rotina interna para distribuir carga; outra é atrasar a oração que o usuário configurou para um momento específico de seu dia. Dez minutos de atraso não é aceitável aqui, por isso deixamos a janela flexível desligada.
Tratamento de Timezone (UTC): O usuário pensa em horário local (9h em America/Sao_Paulo, 9h em America/Campo_Grande). Antes de chegar no Scheduler, combinamos data, hora e timezone e transformamos isso em UTC. O EventBridge recebe a expressão já nessa base, com o ScheduleExpressionTimezone em UTC.
- Isso mantém a infraestrutura simples, mas deixa uma responsabilidade clara na aplicação: nunca misturar horário local com horário de infraestrutura. A regra do produto fala em horário local; o schedule que dispara no backend fala em UTC.
Ao mesmo tempo, acertar o schedule não garante sozinho que a notificação vai aparecer no celular naquele minuto. Depois que o EventBridge Scheduler invoca o target, ainda existe uma longa cadeia de eventos:
[Invocação] ➔ [Cold Start / Latência da Lambda] ➔ [Consultas ao Banco] ➔ [SNS/SQS] ➔ [Entrega do Canal] ➔ [Rede] ➔ [Regras do OS (Android/iOS)]
Depois que a notificação sai do nosso backend, perde-se parte do controle. No Android, o modo Doze pode segurar mensagens quando o aparelho está economizando bateria. No iOS, o APNs trabalha em melhor esforço, e configurações como Focus ou resumos podem mudar o momento em que a notificação aparece. Como nada disso é negociável do nosso lado, a parte importante é reduzir o atraso que está sob nosso controle.

Cuidados com arquitetura serverless
Na primeira versão, o EventBridge publicava em um tópico SNS que tinha uma Lambda inscrita diretamente. A vantagem desse caminho é não ter uma fila explícita sob nosso controle entre o evento e a execução. SNS é push: o evento chega e vira invocação de Lambda sem um buffer nosso regulando o ritmo.
Em termos práticos, é o caminho mais curto entre o schedule disparar e o código rodando. A Lambda escala junto com a taxa de invocação, até o limite da conta. Pra um lembrete que precisa sair perto do horário marcado, esse é o desenho que parece ideal num primeiro momento.
Mas é justamente esse "nada no meio do caminho" que vira o problema seguinte. Pico de schedule tende a virar pico de Lambda no mesmo momento, sem uma fila nossa segurando esse estouro. Essa Lambda ainda precisava decidir se enviava ou não a notificação. Se essa decisão consulta uma dependência síncrona, o limite deixa de ser só Lambda.
Se a dependência seguinte não suporta o número de conexões e leituras criado pelo pico, a escala da Lambda só muda o gargalo de lugar. A arquitetura continua rápida até o próximo limite aparecer.
A partir daí, adicionamos SQS entre o schedule e a execução. Com mais de 11 milhões de notificações por mês, alguns horários concentram bastante processamento, e a fila distribui esse pico em vez de jogar concorrência direta na Lambda.
Mesmo assim, não dá pra deixar tudo escalar sem pensar. SQS transforma pico instantâneo em backlog, mas a Lambda ainda pode escalar demais e estourar a dependência seguinte. Por isso fila não substitui limite: SQS dá fôlego pra Lambda processar no ritmo dela, e o limite de concorrência é o que protege quem vem depois.
Otimizar as dependências da Lambda
Tudo que faz a Lambda demorar mais aparece diretamente na concorrência necessária: cold start, tamanho do bundle, consulta a banco, chamada externa.
100 mensagens/s * 200ms = 20 execuções concorrentes
100 mensagens/s * 2s = 200 execuções concorrentes
Essa conta é simples, mas muda bastante o desenho. Se a Lambda fica dez vezes mais lenta, a mesma carga pede dez vezes mais concorrência. Em pico, isso aumenta a chance de throttle e pressiona a quota regional de Lambda.
O melhor cenário é a Lambda receber no payload tudo que é estável o bastante para ser carregado no evento. Isso reduz I/O, tempo de execução e concorrência necessária. Mas esse cuidado tem limite: estado que pode mudar entre o agendamento e o disparo precisa ser validado perto da execução. No nosso caso, a exceção do dia entra nessa categoria.
Reserved concurrency
Se a API também roda em Lambda, uma fila grande de notificações pode consumir concorrência suficiente para afetar request de usuário.
Pra controlar isso, a gente usa maxConcurrency no event source mapping e reservedConcurrency na função. Os dois limitam quantas execuções dessa Lambda rodam em paralelo. Sem esse limite, um pico de notificações pode consumir boa parte da quota regional e fazer outras Lambdas da conta começarem a tomar throttle.
Outra consequência de usar eventos e filas é idempotência. Criar, atualizar e cancelar schedule precisa tolerar reprocessamento. A gente não pode assumir que cada evento vai ser visto exatamente uma vez, nem que uma tentativa anterior não deixou estado parcial. Nome determinístico de schedule, atualização segura e cancelamento que pode rodar mais de uma vez deixam de ser detalhe.\
Essa arquitetura vai continuar mudando
A primeira versão dessa arquitetura não era essa. A gente passou por várias rodadas de otimização até chegar aqui: na Lambda, nas dependências, na transformação de SNS direto pra fila no meio, no limite de concorrência. Esse tipo de evolução vai continuar acontecendo. Hoje, 11 milhões de notificações por mês já é volume suficiente para mostrar onde os limites aparecem. Se esse número cresce uma ordem de grandeza, o problema não é simplesmente deixar Lambda escalar mais. É saber qual parte da cadeia vai reclamar primeiro.
Como a Fleye ajuda a sua empresa a alcançar essa maturidade técnica?
Se você lidera um time tech, sabe que tirar uma ideia do papel ou escalar um produto digital exige exatamente esse tipo de maturidade em engenharia de software e nuvem. Enfrentar gargalos de banco de dados, picos de concorrência na AWS e arquiteturas assíncronas não precisa ser uma dor solitária do seu time.
A Fleye atua como uma parceira estratégica através do Software Development, fornecendo apoio consultivo e engenharia sênior sob demanda para construir sistemas robustos, modernos e altamente escaláveis.
Nossa experiência prática com desafios de alta escala está documentada em histórias reais de sucesso — como mostramos neste artigo dos bastidores do Capela.
➡️ Saiba mais sobre o nosso serviço de Software Development






